Spatial Domain Storage¶
Spatial domain of a multidimensional dataset can have two different types:
- Grid spatial domain
- Mesh spatial domain
Grid Spatial Domain¶
Grid is fully defined by its definition in dataset.json blob. Grid index is based on the QuadTree algorithm. The index is built in memory from grid definition.
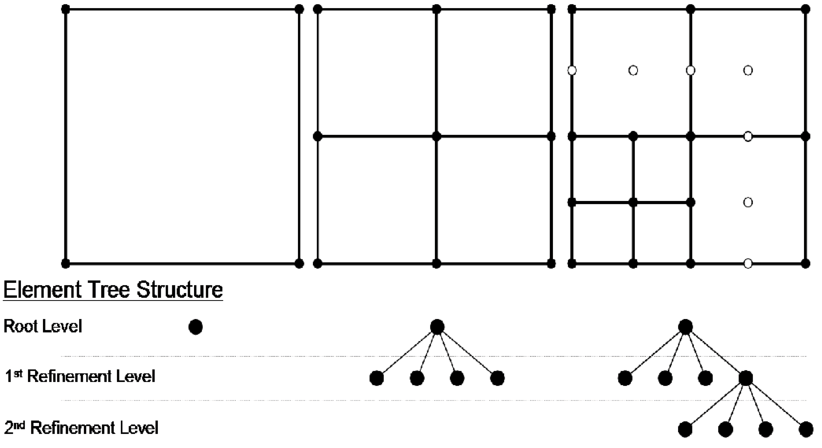
Equidistant and non-equidistant grids are supported.
Mesh Spatial Domain¶
Mesh domains are defined as a collection of Mesh elements. R-Tree spatial index in Sort Tile Recursive implementation from NetTopologySuite is used.
The created index consists of:
- non-leaf nodes : stores a collection of child nodes, and the bounding box (rectangle)
- leaf node - contains mesh elements, so-called 'level 0'
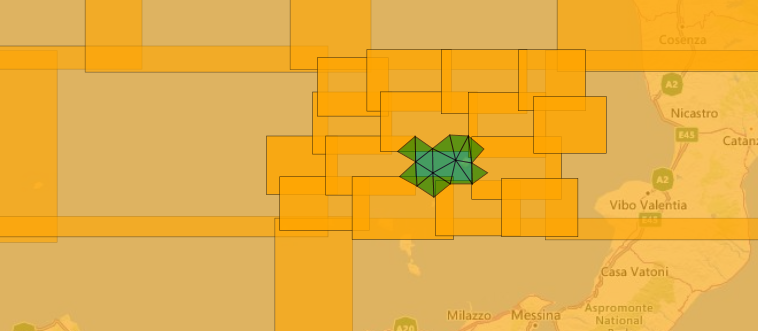
Each node is setup to have at most 16 child nodes. Building the index is computationally expensive operation. For reuse we store the computed R-tree index in 2 files. These files are reused for quick reconstruction of the index during queries.
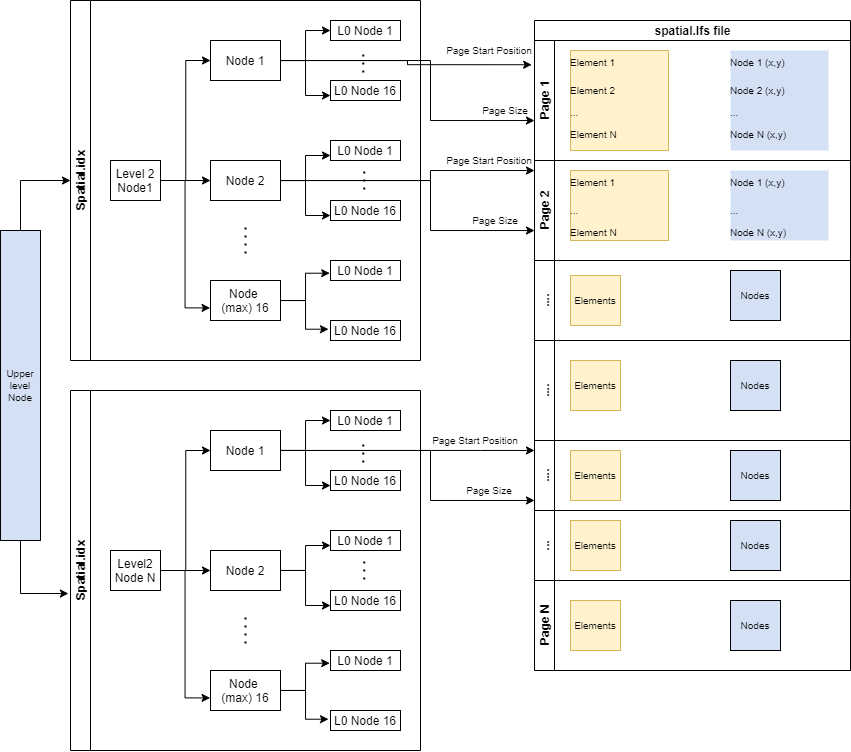
spatial.lfsfile - contains leave nodes (mesh elements).spatial.idxfile - contains non leaf nodes hierarchy.
Mesh node¶
Defined by X, Y position. For static vertical domains an optional Z coordinate can be stored.
Mesh element¶
In a typical mesh, nodes are shared among many elements. Storing each individual element with its full node definition would lead to excessive information storage. For better performance we reuse the node definition among elements. Node coordinates are stored as arrays and element nodes are defined by indexes to the node arrays.
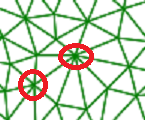
Mesh Page¶
To be able to retrieve only a small number of elements required by the query and fully reconstruct their nodes, we store spatially adjacent set of at most 256 elements as a mesh page.
The 'level 1' of R-tree index ( contains 256 = 16*16 elements) is mapped to a mesh page. Each 'level 1' page contains 'Page start' and 'Page size' values, describing the position and allocation of the page inside spatial.lfs file.
Mesh page binary serialization is applied as performance optimization: - Element node indexes are stored as bytes not integers. This saves 3 bytes * number of nodes per element, i.e. approximately 30% of space. - All nodes are stored with double precision. - Each page fits to 3kB which can be retrieved very quickly from the storage.