MIKE Cloud Platform¶
This documentation describes the MIKE Cloud Platform and how to use it.
The MIKE Cloud Platform is a set of web services that allow storage, query, and analysis of data. Data can be imported as a Dataset using the platform's conversion pipeline into a hierarchy of Projects. When imported, data can be queried, analyzed, converted, or exported again. The query capabilities depend on what data formats you work with an how you decide to import the data.
Platform's REST API can be used from almost any programming language, but most interactions use our dotnet SDK or Python SDK. The SDKs are very similar, this documentation covers primarily the dotnet SDK. To get started with the SDKs, explore the How-to guides in the SDK section and other resources on develop.mike-cloud.com.
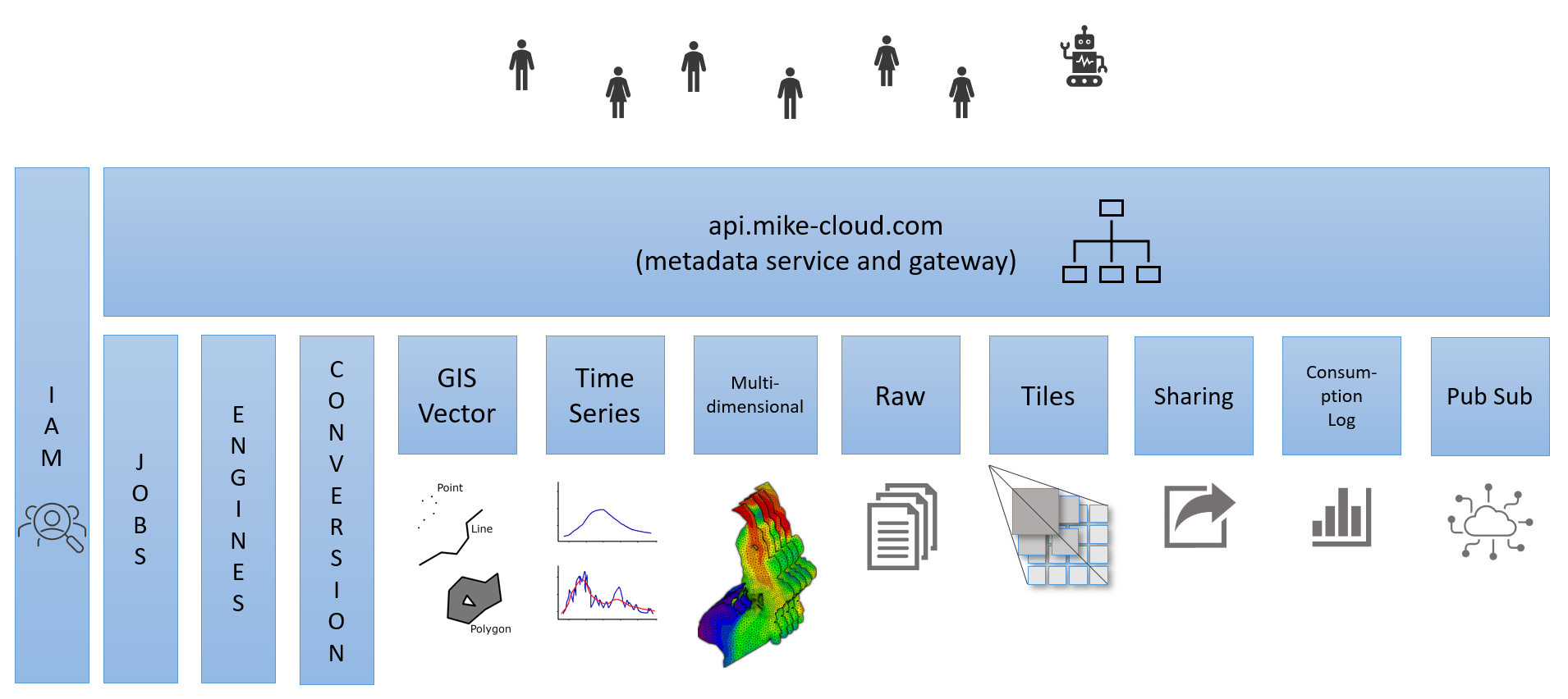
Metadata Services¶
The data model of the water data core services revolves around the concept of a Project, which contains Datasets. The Metadata Service host is a single web application which hosts several services and provides API to manage projects, dataset descriptions (also referred to as metadata, or dataset), and also Transfer objects used during imports, exports, and conversions.
Project Service¶
The main entity managed by the Project Service is a Project - a logical grouping of Datasets. One Dataset always belongs to exactly one Project, although other projects can reference a dataset with a "read-only link" (see Sharing Service for details). One Project always belongs to exactly one Customer and a Project must have at least one Customer User associated as an owner of the Project. Project owners or customer administrators can add other users of the Project with a specific Role (Owner, Contributor, Reader). An Access Level level of a Project can be set to Confidential, Private, or Shared (within a customer). Projects can be organized into hierarchies of subprojects, also referred to as folders.
Dataset Service¶
The Dataset entity managed by the Dataset Service represents a real dataset, but the Dataset entity itself contains only descriptive information, which is sometimes referred to as "dataset definition" or "metadata" (not to be confused with the Metadata property of all our entities). Actual data values are managed by Data Services or stored as files in Raw File Storage
Transfer Service¶
The Transfer Service manages Transfer entities and plays crucial part in getting data in to or out of the platform (Import and Export pipelines). A Transfer type is predetermined to be either Upload or Download when the Transfer is created. It also provides possibilities for data conversion within the platform. This functionality is referred to as the Conversion Pipeline.
Sharing Service¶
Service id: sharing
The Sharing Service is a stand-alone service which provides mechanism for sharing of datasets across projects and even across customers. It manages entities Catalog, Publication, and Subscription.
Identity and Access Management services¶
Identity and Access Management Service (IAM)¶
Service id: iam
IAM service is a standalone service used for user authentication. It generates security tokens used throughout the platform for user identification. The token includes also a list of scopes defining authorization, e.g. whether the user is allowed to use certain endpoints. Note that within the platform, another level of authorization is provided by user membership on the projects in metadata service. However, the IAM service can be used without the platform services.
Data services¶
Each data service specializes on storing data values of specific data formats and offers specific query capabilities or APIs.
File Storage service¶
Service id: raw
Stores data in its original form in the format they were imported in. The File Storage service does not offer many fancy APIs, but it is the most universal storage in the platform and an ideal place for storing files as they are.
Time Series Service¶
Service id: timeseries
The Time Series Service handles plain time series data such as measurements from monitoring stations or calculated series from points.
Multidimensional Service¶
Service id: md
The Multidimensional Service handles multidimensional data, typically stored in DFS2, DFS3, DFSU, or NetCDF files in the desktop environment. Data in the Multidimensional Service can be queried for example using spatial, temporal, and layer filters.
GIS Service¶
Service id: gis
The GIS Service is dedicated for vector spatial data, i.e. geometries (points, lines, polygons, or multi-polygons) associated with attribute values.
Coordinate Systems Service¶
Service id: coordinatesystems
Archive of available coordinate system definitions known to the platform. The service also provides an end point to transform a list of geometries (of the same type) from one coordinate system to another.
Compute (execution) services¶
Conversion Pipeline¶
Service id: none
The Conversion pipeline enables import, export, and conversion of data. Executing either of these operations creates a Transfer entity. The Transfer represents an asynchronous task with handles the data. Executing import, export, or conversion typically involves interaction with multiple end points on the Metadata Service host.
Engine Execution Service¶
Service id: engine
Service for executing modelling engines like MIKE 21 FM, MIKE 1D, and more.
Job Service¶
Service id: job
Service for executing predefined jobs based on containers.
Contact¶
Cannot find what you came for? Contact mike@dhigroup.com For even more information about the platform reach out to wdpservice@dhigroup.com