Hardware configurations
Intro¶
Engine execution is running in Microsoft Azure cloud and at the moment is heavily reliant on Microsoft Azure provided services. The most prominent of those are Azure Batch and Storage Account.
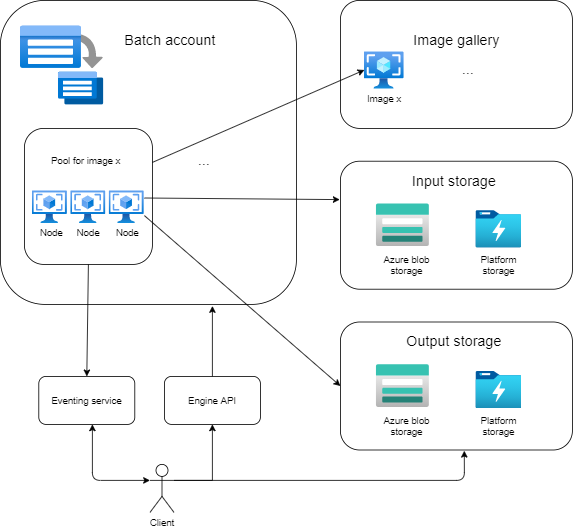
Microsoft Azure services¶
Image Gallery¶
Is a repository for managing and sharing Azure VM images. Azure VM images could be exchanged with Docker images and Image Gallery with Docker image gallery.
Storage Account¶
Azure Batch accounts have at least one storage account for storing all the data related to pools, applications, etc. In the current solution storage accounts are also used for storing inputs to the engine execution (at the moment this storage account is expected to be managed and provided by client). Outputs from engine execution are also saved in the storage account. The following storage account is managed by either platform team or client if provided in the call to the engine execution.
Azure Batch¶
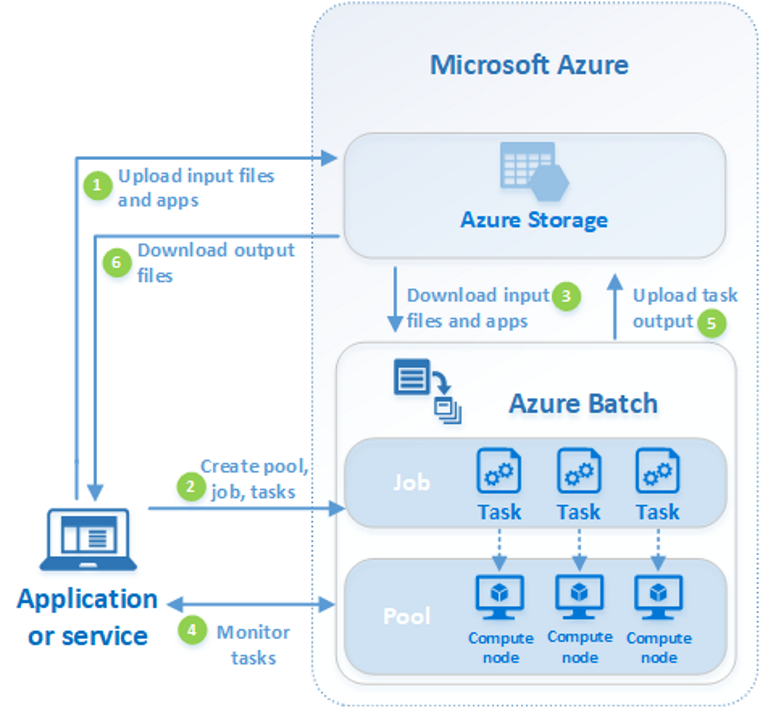
Pool: is a pool of nodes that the application is run on. Among pool configurations is application package which is copied to each node, VM type and configurations, scaling policy, target size of pool. A pool can be dynamically created (but it seems to be time consuming process) and dynamically chosen via API.
Read more here about how to get a full list of available pools and their configurations.
Job: a job is a collection of tasks. Job specifies a pool in which a task is to be run. It is possible to both create a pool for each job or to use one pool for many jobs.
In current engine execution implementation we have one job per pool except dev environment were dev and dev0 jobs are on the same pool.
Task: is a unit of computation and runs on a node.